Параллельное программирование#
Цель - повышение производительности, эффективное использование вычислительных ресурсов.
Последовательные вычисления - имеется единственная инструкция выполняемая в данный момент времени.
Параллельные вычисления - несколько инструкций выполняются одновременно.
Типы задач в которых распараллеливание вычислений может помочь:
Вычислительно-сложные (CPU-bound)
С задержками на ввод-вывод (IO-bound, большие задержки и/или большие объемы данных)
Критический путь#
При распараллеливании вычислительно-сложные задачи имеют ограничение на увеличение производительности определяемое т.н. критическим путем.
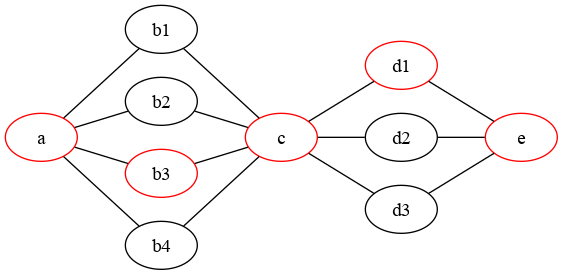
Путь a - b3 - c - d1 - e является критическим и определяет наименьшее возможное время выполнения. Добавление узлов для параллельного вычисления b1 - b4 и d1 - d3 не даст сокращения общей продолжительности вычислений.
Виды параллелизма с прикладной точки зрения#
Вид параллелизма |
Число ядер |
Число узлов |
Оперативная память |
Примечание |
|---|---|---|---|---|
Параллелизм на уровне данных |
1 |
1 |
- |
SIMD, происходит незаметно для нас на уровне процессора/компилятора |
Кооперативная многозадачность |
1 |
1 |
Общая |
Корутины/async-await, только для IO-bound задач |
Специализированные сопроцессоры |
N |
1 |
Изолированная |
Вычисления на видеокартах |
Потоки |
N |
1 |
Общая |
|
Процессы |
N |
1 |
Изолированная |
|
Однородные вычислительные кластеры |
N |
N |
Изолированная |
Вычислительные кластеры |
Гетерагенные вычислительные кластеры |
N |
N |
Изолированная |
Распределенные вычисления |
Параллелизм на уровне данных#
На примере сложения чисел А1, A2 и B1, B2. C1 и C2 - результаты сложения:


Кооперативная многозадачность#
Последовательное выполнение#

Кооперативное выполнение#

Вытесняющая многозадачность#

Проблемы с вытесняющий многозадачностью#
Доступ к разделяемым ресурсам
Состояние гонки
Взаимные блокировки
Активное ожидание
Способы преодоления#
Мьютексы (Mutex)
Барьеры (Barrier)
Критические секции (Critical section)
Обмен сообщениями
Сокеты (socket)
Модель издатель-подписчик (pub-sub)
Очереди (queue: FIFO, LIFO)
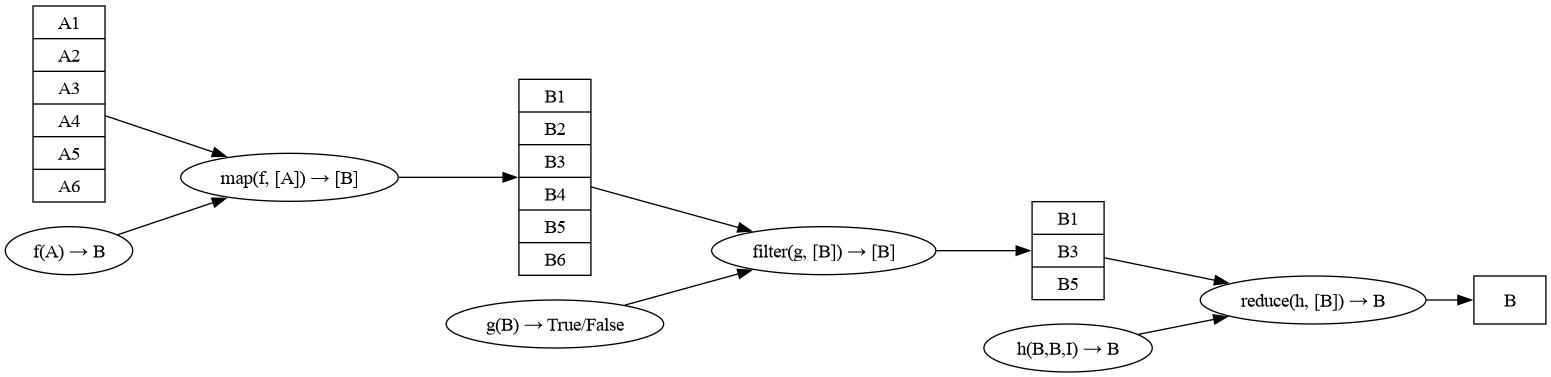
Парадигма map-reduce#
Есть способ записи программ способствующий их эффективному распараллеливанию - парадигма map-reduce.
Замечание о параллельных вычислениях с использованием пакета NumPy#
По умолчанию пакет NumPy использует внутреннее распараллеливание и задействует все доступные ядра, если это возможно. Подавить данное поведение можно следующими переменными окружения:
import os
os.environ['OPENBLAS_NUM_THREADS'] = '1' # для NumPy собранной с OpenBLAS
os.environ['MKL_NUM_THREADS'] = '1' # для NumPy собранной с MKL
Параллелизм на уровне данных#
import timeit
import numpy as np
import array
# Подготовка данных
cns = 42
s = 100
count = 10
data = []
result = []
# Реализации умножения матриц
# На списках
for _ in range(0,s):
data.append([float(x) for x in list(range(cns,cns+100))])
result.append([float(x) for x in list(range(cns,cns+100))])
cns+= 1
def matmul1():
for m in range(s):
for n in range(s):
result[m][n] = 0.0
for o in range(s):
result[m][n] += data[m][o] * data[o][n]
# На массивах
fdata = []
for row in data:
fdata += row
adata = array.array('d', fdata)
aresult = array.array('d', fdata)
def matmul2():
for m in range(s):
for n in range(s):
aresult[m*s + n] = 0.0
for o in range(s):
aresult[m*s + n] += adata[m*s + o] * adata[o*s + n]
# С использованием NumPy
ndata = np.array(data)
nresult = np.zeros(ndata.shape)
def matmul3():
global nresult
nresult = np.zeros(ndata.shape)
nresult = np.dot(ndata, ndata)
# Измеряем скорость
print(timeit.timeit(matmul1, number=1))
print(timeit.timeit(matmul2, number=1))
print(timeit.timeit(matmul3, number=1))
Запуск параллельных вычислений с использованием пулов потоков и процессов#
Запуска многопоточного выполнения функции через ThreadPoolExecutor#
from time import sleep, time
import numpy.random as random
from concurrent.futures import ThreadPoolExecutor
#поскольку мы запускаем потоки, то можем сохранять результаты
#в общую переменную common_data
common_data = []
#если sleep в этой функции заменить вычислениями, то
#прибавки в производительности между 1 и несолькими потоками
#не будет из-за работы Python GIL. ходят слухи, что в 3.14 это изменится...
n_threads = 3
def work(i):
sleep(random.random())
common_data.append(i**2)
print(f'Task {i} is complete\n', end="")
data = list(range(8))
results = []
stime = time()
with ThreadPoolExecutor(n_threads) as executor:
executor.map(work, data)
executor.shutdown()
ptime = time()
print(common_data, "in", ptime-stime, "sec")
Task 1 is complete
Task 0 is complete
Task 2 is complete
Task 5 is complete
Task 3 is complete
Task 4 is complete
Task 7 is complete
Task 6 is complete
[1, 0, 4, 25, 9, 16, 49, 36] in 1.3230907917022705 sec
Запуска выполнения функции в нескольких процессах через ProcessPoolExecutor#
from time import sleep, time
import numpy.random as random
from concurrent.futures import ProcessPoolExecutor
#поскольку мы запускаем процессы, то мы не можем сохранять результаты
#в общую переменную common_data - этот список останется пустым
common_data = []
#рост производительности будет пропорционален числу процессов n_procs,
#но ограничен числом ядер процессора данного компьютера
#использование процессов позволяет преодолеть проблему GIL
n_procs = 3
def work(i):
sleep(random.random())
common_data.append(i)
print(f'Task {i} is complete\n', end="")
return i**2
#поскольку по факту будет запущено несколько копий данного скрипта
#код запускающий ProcessPoolExecutor должен быть оформлен в блоке __main__,
#а код реализующий вычисления - в виде глобальной функции
if __name__ == '__main__':
data = list(range(8))
stime = time()
with ProcessPoolExecutor(n_procs) as executor:
ft = executor.map(work, data)
executor.shutdown()
ptime = time()
print(common_data) # пусто
print(list(ft), " in ", ptime-stime, " sec") # результаты собранные через return
Task 1 is complete
Task 0 is complete
Task 2 is complete
Task 4 is complete
Task 3 is complete
Task 5 is complete
Task 6 is complete
Task 7 is complete
[]
[0, 1, 4, 9, 16, 25, 36, 49] in 1.8475453853607178 sec
import random
from time import sleep, time
from concurrent.futures import ThreadPoolExecutor
#В новых версиях python есть реализация разбивания списка на чанки в модуле itertools
def batched2(data):
result = []
for i in range(0,len(data),2):
result.append([data[i],data[i+1]])
return result
#Реализация класса для простого map-reduce. Может использоваться с любым пулом
class SimpleMapReducePool:
def __init__(self, pool):
self.pool = pool
def map(self, fn, data):
return list(self.pool.map(fn, data))
def filter(self, fn, data):
r = list(self.pool.map(fn, data))
return [x for i,x in enumerate(data) if r[i]]
def reduce(self, fn, data):
if len(data) == 0:
return None
if len(data) == 1:
return data[0]
if len(data) % 2 == 0:
bt = batched2(data)
return self.reduce(fn,list(self.pool.map(fn, bt)))
else:
bt = batched2(data[:-1])
return self.reduce(fn,list(self.pool.map(fn, bt)) + [data[-1]])
#Задача: находим колисчество символов с самой короткой непустой строке
data = ["mklsf", "", "woiejfwe", "km", "oiejwefw", "pujskdlfjiejsmd", "", "", "sdfe"]
#Подсчет символов
def count_symbols(s):
sleep(1)
return len(s)
#Фильтр пустых строк
def fiter_empty(n):
sleep(1)
return n > 0
#Поиск наиболее короткой строки
def find_min(x):
sleep(1)
a,b = x
return min(a,b)
#Все замечания о работе с ThreadPoolExecutor и ProcessPoolExecutor уместны и тут
n_worker = 3
start = time()
p = SimpleMapReducePool(ThreadPoolExecutor(max_workers=n_worker))
result = p.reduce(find_min,p.filter(fiter_empty, p.map(count_symbols, data)))
end = time()
print(result, " in ", end-start, " sec")
2 in 9.005588054656982 sec
Task 1 is complete
Task 2 is complete
Task 4 is complete
Task 6 is complete
Task 7 is complete
Task 0 is complete
Task 3 is complete
Task 6 is complete
Task 7 is complete
Task 0 is complete
Task 5 is complete
Task 0 is complete
Task 4 is complete
Task 7 is complete
Запуск параллельных вычислений с использованием MPI#
MPI - программный интерфейс (API), который позволяет обмениваться сообщениями между несколькими процессами, выполняющими одну и туже задачу. Существует несколько реализаций.
Для работы с MPI в Windows нам понадобятся:
пакет
mpi4pyизpipустановить Microsoft MPI: https://www.microsoft.com/en-us/download/details.aspx?id=57467
Для работы с MPI в Linux нам понадобятся:
пакет
mpi4pyизpipпакет
openmpi(системный или изpip)
Чтобы запустить процесс с использованием MPI следует использовать следующую команду:
mpiexec -n 4 python file.py
где -n 4 - число процессов при локальном запуске или -hostfile hosts.txt - файл с перечислением доступных узлов для запуска на вычислительном кластере. Узлы должны быть доступны по SSH для входа от имени текущего пользователя без пароля и на них должна быть установлена совместимая версия openmpi.
Рассылка данных исполнителям с использованием MPI#
В этом примере процесс с рангом 0 рассылсает по одному сообщению всем остальным процессам, они его получают:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
data = [x+42 for x in range(size - 1)]
print("Worker", rank, "send data", data)
for i in range(1, size):
comm.send(data[i-1], dest=i, tag=11)
else:
d = comm.recv(source=0, tag=11)
print("Worker", rank, "get data", d)
Worker 0 send data [42, 43, 44]
Worker 1 get data 42
Worker 3 get data 44
Worker 2 get data 43
Пакетное взаимодействие через MPI#
В этом примере процесс с рангом 0 рассылсает данные всем процессам (в том числе себе):
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
buffer_before = np.empty([size, 4], dtype='i')
buffer_after = np.empty([size, 4], dtype='i')
local_buf = np.empty(4, dtype='i')
if rank == 0:
for i in range(0,size):
buffer_before[i,:] = (i+1)*42
print("worker", rank, "send data:\n", buffer_before)
comm.Scatter(buffer_before, local_buf, root=0)
print("worker", rank, "gets", local_buf)
local_buf = local_buf // 2
print("worker", rank, "send", local_buf)
comm.Gather(local_buf, buffer_after, root=0)
if rank == 0:
print("worker", rank, "get data:\n", buffer_after)
worker 0 send data:
[[ 42 42 42 42]
[ 84 84 84 84]
[126 126 126 126]
[168 168 168 168]]
worker 0 gets [42 42 42 42]
worker 2 gets [126 126 126 126]
worker 1 gets [84 84 84 84]
worker 0 send [21 21 21 21]
worker 2 send [63 63 63 63]
worker 1 send [42 42 42 42]
worker 3 gets [168 168 168 168]
worker 3 send [84 84 84 84]
worker 0 get data:
[[21 21 21 21]
[42 42 42 42]
[63 63 63 63]
[84 84 84 84]]
Запуска выполнения функции в нескольких процессах через MPIPoolExecutor#
MPIPoolExecutor работает также, как и ProcessPoolExecutor рассмотренный ранее.
Процесс в блоке __main__ имеет rank = 0.
Запуск данного кода следует производить командой:
mpiexec -n 4 python -m mpi4py.futures file.py
from mpi4py import MPI
from mpi4py.futures import MPIPoolExecutor
from time import sleep, time
def work(i):
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
sleep(1)
print("worker", rank, "done")
return i
if __name__ == '__main__':
data = list(range(8))
results = []
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
start = time()
with MPIPoolExecutor() as executor:
s = executor.map(work, data)
end = time()
print("worker", rank, "done:", list(s), "in", end-start, "sec")
worker 1 done
worker 3 done
worker 2 done
worker 1 done
worker 3 done
worker 2 done
worker 3 done
worker 2 done
worker 0 done: [0, 1, 2, 3, 4, 5, 6, 7] in 3.0202248096466064 sec